初探数据爬取和可视化分析
字数 3.4k / 13 min 读完 / 阅读 毫无疑问互联网已经深入到我们生活的方方面面,上面每天承载着海量的数据。作为一名对网络技术有些追求的程序猿,如果从海量信息中抓取我们所关心的那些数据而为我所用,似乎是一件特别有意思的事情。下面我们将以《王者荣耀》为切入点,告诉如何利用简单的爬虫,抓取指定数据,再将数据聚合进行可视化的分析。
1.Charles抓包分析目标接口
Charles是一款很实用,界面很友好(至少跟fiddler比起来),功能强大的抓包神器,因为它是基于 java 开发的,所以跨平台,Mac、Linux、Windows下都是可以使用的,并且在Android和iOS设备上通用。它的原理是通过成为电脑或者移动设备的代理截取请求和请求结果达到分析抓包的目的。
工具的具体使用方法,在网上已经有很多非常详细的教程了,这里就不再赘述了。我们这边只归纳一下大致的操作步骤:
1.保证手机WiFi和PC网络同处在同一局域网,PC端启动Charles,开启代理服务
2.手机WiFi网络配置上述的代理服务器IP
3.针对Https的网络请求,需要提前在手机上安装ssl证书
4.使用手机进行网络请求,在Charles上分析我们需要的请求
这里我们需要强调一下第3步,为什么对于Https的请求,我们需要在手机上额外安装ssl证书呢?
我们可以从下面两个方面看。
第一,在客户端发出Https请求时, Charles充当了服务器的角色,需要返回一个证书给客户端,但是Charles的证书并不是CA机构颁发的,客户端一验证就知道是假的连接肯定就断了,那怎么办呢?那就想办法让客户端信任这个服务端,于是就在客户端安装一个Charles的根证书。所以只要是通过Charles的Https请求,验证根证书时自然会通过,因为Charles的根证书你已经受信了!
第二,现在只是客户端和Charles这个伪服务端的Https验证通过了,还没有到真正的服务端去取数据的,此时Charles会以客户端的身份与真正的服务端再进行一次HTTPS的验证,最后拿到数据后又以服务端的身份与客户端通信。也就是说在一次请求中数据被两次加解密,一次是手机到Charles ,一次是Charles到真正的服务端。
整个请求的流程,可以简化用下图更直观的表现出来。
这里我们利用《王者荣耀》小程序的,抓取小程序的接口数据就可以得到我们需要爬取的数据接口

具体抓到的接口如下:
1.获取英雄详情: |
2.Python爬虫抓取样本数据
该环节主要使用python中的requests库来进行数据请求,自定义了数据爬取逻辑,针对爬取的数据统一存放到Mysql数据库
2.1 爬虫思路
利用【获取比赛详情】接口,单场比赛可以查看10个用户的比赛数据,其中包含了用户open_id,有了open_id之后,我们又可以继续爬取该用户下的所有参赛数据了,这样就可以无限爬取了。
2.2 目前存在的坑
微信后端有做限制,对于与自己没有任何关系(好友关系或者对战关系)的用户,无权查看该用户的opend_id。也就是说,如果以我自己的opend_id作为爬虫的源头,我只能爬与我比赛过的所有用户的全部对战情况。这样的话,数据的爬取深度就直接减到最低了,因此我们的爬取策略,就只能是拓展广度。目前针对数据深度受限问题,无解~,这个问题也可以通过下面的例子直观的看出来。

如上图,单个用户0的一场比赛,会有用户1,用户2,用户3 共10个用户(包括自己)参与,而且通过用户1的用户详情,我们可以查看用户1的每场比赛,因此可以取到用户4,用户5,用户6的用户详情。这样下来,我们获得的用户数将成几何级倍数疯狂的增加,可以这么说,我们以一个用户为起点,就可以取得全网所有的用户数据和对战数据了,显然,这是微信不愿意看到的。因此微信在对战关系的层级上做了限制,一个用户只能查看与其发生过对战的用户的数据。
2.3 设计实现
针对数据方面,为了方便存储和后续的数据处理,我们采用mysql来做数据存储,共设计了四张表:和我们关心的用户数据,英雄数据,对战数据,我们设计了四张表,方便我们存储和处理数据。
1.battle:对战表,包含单场比赛的简要数据,如比赛类型,时长,双方杀敌数,比赛结果等。
2.hero:英雄表,包含游戏中英雄id,英雄类型,英雄名称等
3.user:用户表,包含用户open_id,游戏区id,昵称,服务器名称,胜率,段位等信息
4.user_battle_detail:用户对战详情表,包含比赛id,对战用户open_id,杀死助数量,kda评分等
5.user_hero:用户英雄表,包含单个用户所有已持有英雄。
代码的主实现逻辑如下:
def start_work(): |
本来是设计使用队列,采用多线程的方式批量爬取,后面发现微信游戏服务器针对接口爬取有调用频率的限制,因此实际是采用单线程在处理。
3.数据同步到ElasticSearch
mysql数据库同步到ES大都是利用mysql的binlog日志来实现,binlog主要用于数据库的主从复制与数据恢复。binlog中记录了数据的增删改查操作,主从复制过程中,主库向从库同步binlog日志,从库对binlog日志中的事件进行重放,从而实现主从同步。这里从主库同步到ES其实是一个道理。
这类同步处理,目前有各种不同的方案:
1.go-mysql-elasticsearch,项目github地址:https://github.com/siddontang/go-mysql-elasticsearch
2.mypipe,项目github地址:https://github.com/mardambey/mypipe
3.logstash-jdbc-input,logstash的一个插件
我们采取第三种,即logstash-jdbc-input,这个也是ElasticSearch官方推荐的一种方式(毕竟是自己公司的产品,不推荐你推荐谁,/手动滑稽 -_-!)
下面进入正题,在logstash的使用方面,我们需要进行如下配置,保证我们需要的数据能正常同步。
新增scrawler_user_battle_detail.cfg,用来同步user_battle_detail表;
新增scrawler_battle.cfg,用来同步battle表;
新增scrawler_hero.cfg,用来同步hero表;
新增scrawler_user_hero.cfg,用来同步user_hero表;
其中,scrawler_user_battle_detail.cfg配置如下
input { |
这里我们采用了增量同步的方式来完成数据的同步。上述的sql_last_value为工具的内置变量,每个表都有一个update_time的时间戳字段,没同步一次,最新的update_time就会赋值给sql_last_value,等到下一个同步周期时,就只取sql_last_value时间之后产生的数据来进行同步了,schedule为同步的时间配置,这里*/60 * * * * *表示每隔一分钟同步一次。对于我们目前的数据要求,一分钟同步一次足够了。
完成了上述配置,还需要创建pipeline.cfg来引用上述的四个配置文件,来使之生效。
pipeline.cfg配置如下:
- pipeline.id: scrawler_battle |
4.利用Kibana进行数据的可视化分析
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作(Kibana、Elasticsearch、Logstash属于同一家公司的产品)。使用Kibana,我们可以轻松的搜索,查看,并和存储在Elasticsearch索引中的数据进行交互。
Kibana 搭载了一些经典功能:柱状图、线状图、饼图、环形图等等,充分利用了Elasticsearch 的聚合功能,而且Dashboard功能能够将各种可视化组件集合成大屏,是数据更直观,可参见如下
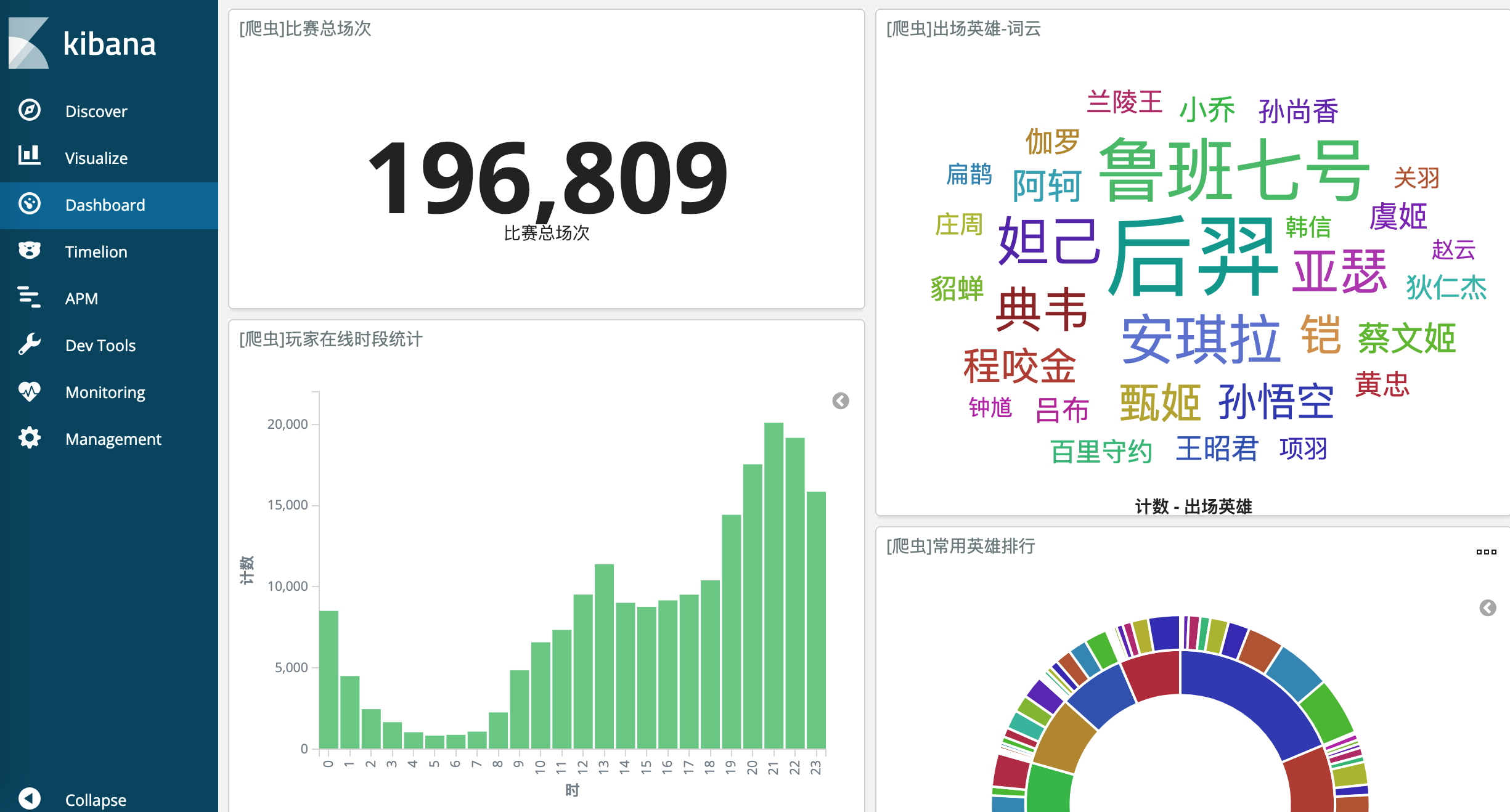
可见,一个Dashboard是由若干个图表排列组合而成,具体的单个图表,是在Visualize中通过不同的数据过滤聚合而来。目前Kibana提供的图标形式有如下几种:
1、Area :用区块图来可视化多个不同序列的总体贡献。
2、Data :用数据表来显示聚合的原始数据。其他可视化可以通过点击底部的方式显示数据表。
3、Line :用折线图来比较不同序列。
4、Markdown : 用 Markdown 显示自定义格式的信息或和你仪表盘有关的用法说明。
5、Metric :用指标可视化在你仪表盘上显示单个数字。
6、Pie :用饼图来显示每个来源对总体的贡献。
7、Tile map :用瓦片地图将聚合结果和经纬度联系起来。
8、Timeseries :计算和展示多个时间序列数据。
9、Vertical bar :用垂直条形图作为一个通用图形。
下面回归到我们关心的样本数据上,本次共抓取了2万场左右的对战数据,就英雄的出场率,玩家在线情况,不同英雄kda得分等情况进行了分析。
- 英雄出场次数统计

该数据以词云形式展示,文字大小对应了数据出现的频率。很显然,后羿、鲁班七号、安琪拉为大部分玩家的首选英雄。
玩家在线时间段统计

该数据以柱状图的形式展现,看得出每天晚上8点至11点为玩家上线的高峰期,另外中午12点至下午1点有一个小高峰,可能是因为小学生和女大学生都下课了。
英雄kda评分分布

该数据以热力图形式展示,纵轴为kda评分,方块的颜色深浅代表英雄得到对应评分的次数。在当前样本中,后羿以6-10的评分排到最高,即大部分的后羿评分都在这个区间。
5.结语
当然这里只是抛砖引玉,简单的叙述了从数据抓取到可视化分析的流程和步骤,针对实际操作中,会遇到各种各样的实际难题,也会有各种各样解决方案。你可以根据你工作需要、兴趣爱好从互联网上取得任何你感兴趣的数据,从自己的视角做一些更有意义的分析。
科技日新月异,而你,需要不断前行!
附:
1.本文涉及的Kibana地址: http://39.108.71.75:5601/app/kibana (该链接后期可能清除,不保证链接长期可用)